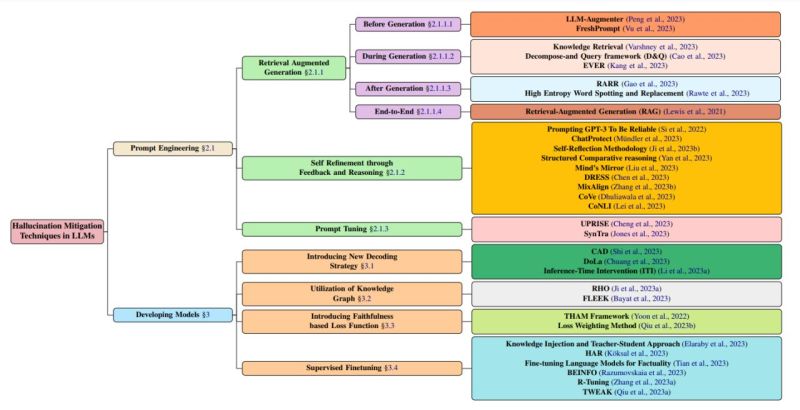
The paper provides a comprehensive taxonomy categorizing over 32 techniques for mitigating hallucinations in large language models (LLMs). It groups the techniques into categories such as prompt engineering, self-refinement through feedback and reasoning, prompt tuning, and model development. Key mitigation techniques highlighted include:
Retrieval Augmented Generation (RAG) which enhances LLM responses by retrieving information from authoritative external knowledge bases. This helps ground the responses in facts.
Methods leveraging iterative feedback loops and self-contradiction detection to refine LLM outputs. For example, the Self-Reflection Methodology employs knowledge acquisition and answer generation over multiple cycles.
Prompt tuning techniques like UPRISE which tune lightweight retrievers to automatically provide task-specific prompts that reduce hallucinations.
Novel model decoding strategies such as Context-Aware Decoding that override an LLM’s biases by amplifying differences between outputs with and without context.
Utilizing knowledge graphs and adding faithfulness based loss function
Supervised Fine-tuning